
Denne artikel handler om teknisk SEO. I artiklen finder du en kort introduktion til, hvad teknisk SEO er, og hvorfor det er vigtigt. Vi deler også vores tips til, hvordan du overordnet set bør arbejde med teknisk SEO, og hvordan du får skabt en god process. Endelig kommer vi omkring det tekniske SEO audit, herunder hvilke elementer du bør have med, og hvordan du kan handle på de problemer, der dukker op i den tekniske SEO-analyse.

Hvorfor er teknisk SEO vigtigt?
Teknisk SEO er fundamentet for dit websites organiske performance. Du kan have det bedste indhold i verden, de stærkeste links og den fedeste brugeroplevelse, men hvis Google ikke kan crawle og indeksere din hjemmeside, er det ligegyldigt. Teknisk SEO er således ikke noget, der i sig selv vil forbedre dine rankings, men det er en forudsætning for, at din hjemmeside overhovedet kan komme til at ranke.
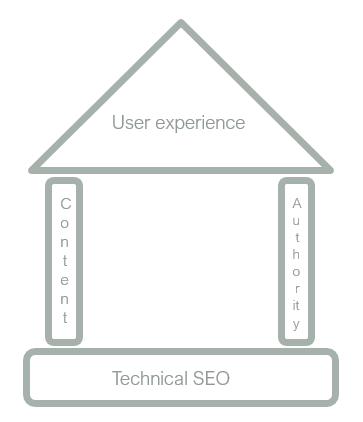
Derfor anbefaler vi altid, at du sørger for at have det tekniske fundament i orden, før du bruger en masse ressourcer på de andre SEO-faktorer. Når den tekniske SEO på din hjemmeside er i top, kan du begynde at optimere på de andre parametre, da du nu vil få det fulde udbytte af dine investeringer i content, links og en god brugeroplevelse.
Hvad er teknisk SEO?
Basal teknisk SEO handler om at sikre, at Google kan crawle, rendere og indeksere indholdet på din hjemmeside. Dertil kommer discipliner som hastighedsoptimering, forbedring af performance på Core Web Vitals, implementering af schema markup og sikring af god navigationsstruktur. Disse elementer er også tekniske af karakter, men handler mere om at forbedre brugernes oplevelse på hjemmesiden end at sørge for, at de overhovedet kan finde den. Derfor holder vi os i denne artikel til de basale elementer: crawlability, rendering og indeksering.
Vil du læse mere om PageSpeed og Core Web Vitals, har vi en artikel om emnet her.
1. Crawlability
Crawlability går ud på at sikre, at Googles crawler har adgang til at crawle alt det indhold, som du ønsker, at dine brugere skal kunne finde på din hjemmeside. Crawling er nemlig en forudsætning for, at Google kan finde, indeksere og præsentere indholdet på din hjemmeside for din målgruppe.
Lidt forsimplet foregår crawling ved, at Googles crawler, kaldet GoogleBot, besøger din hjemmeside. Når GoogleBot lander på din hjemmeside, vil den begynde at følge alle de links til undersider, den kan finde. På de fundne undersider vil den finde nye links, som den kan crawle. Denne process gentages så, indtil GoogleBot mener den har fundet alle undersiderne på din hjemmeside.

GoogleBot vil fra tid til anden besøge din hjemmeside for at se, om der skulle være dukket nye sider op. Hvor ofte GoogleBot kommer forbi afhænger af flere faktorer, herunder hvor ofte din hjemmeside opdateres med nyt indhold, hvor populær din hjemmeside er, hvor ofte der linkes til den fra andre steder på nettet, samt hvor effektivt Google kan crawle hjemmesiden.
Opnå god crawlability
Hvordan sikrer du så optimal crawlability på din hjemmeside? Der er mange elementer, der har indflydelse på hvordan en hjemmeside crawles, men de vigtigste er at:
- Undgå orphan pages, døde interne links og redirect fejl
- Sikre korrekt opsætning af robots.txt og meta robots tags
- Oprette og indsende XML sitemaps
Ovenstående termer kan lyde ret tekniske, men lad os prøve at bryde det ned.
Orphan pages
Orphan pages, eller forældreløse sider som man kunne kalde dem på dansk, er sider på din hjemmeside, som der ikke linkes til fra de øvrige sider. Nu hvor vi ved, at Google crawler din hjemmeside ved at følge links fra side til side, kan du sikkert gætte hvorfor dette er et problem.
Har en underside ingen links, er der en risiko for, at GoogleBot aldrig opdager den. For at undgå orphan pages er det vigtigt at sikre en god intern linkstruktur. Dette kan opnås ved at sørge for, at din menu rummer alle relevante sektioner på din hjemmeside, at undersider linker indbyrdes til hinanden, og ved hjælp af SEO-tools der kan identificere orphan pages for dig.
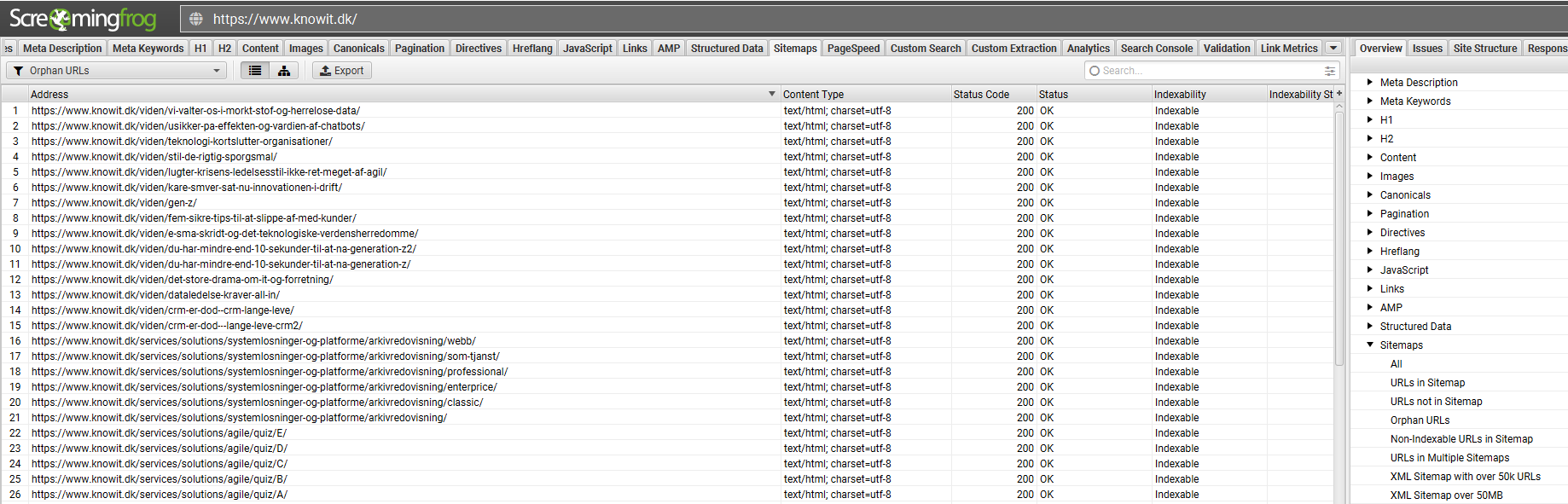
Hvis du vil finde orphan pages er SEO værktøjet Screaming Frog et godt valg. Med Screaming Frog kan du crawle din hjemmeside på samme måde som Google Bot gør det. Herefter kan du få vist en list med alle dine orphan pages.
Døde interne links
Ligesom orphan pages gør døde interne links det besværligt for GoogleBot at crawle din hjemmeside. Et dødt internt link opstår, hvis du på underside A linker til underside B, og underside B herefter ophører med at eksistere eller ændrer URL. Følger Googles crawler, eller en bruger for den sags skyld, et dødt internt link, vil de møde en 404-side, hvilket fører til spildt crawl budget og en dårlig brugeroplevelse.
Enkelte døde links til sider opstår ofte, hvis du manuelt vælger at fjerne undersider, og glemmer at fjerne links til dem. I større skala kan ting som ændringer i URL-struktur, migreringer eller skift til https, skabe en stor mængde døde interne links. Derfor er det vigtigt, at du sørger for at opdatere interne links, hvis du flytter, eller helt fjerner, den side, der linkes til.
Redirect fejl
Redirect fejl kan også give problemer for GoogleBot, når den skal crawle din hjemmeside. Et redirect skal gerne ende på en side med en statuskode 200, det vil sige en aktiv og fungerende side.
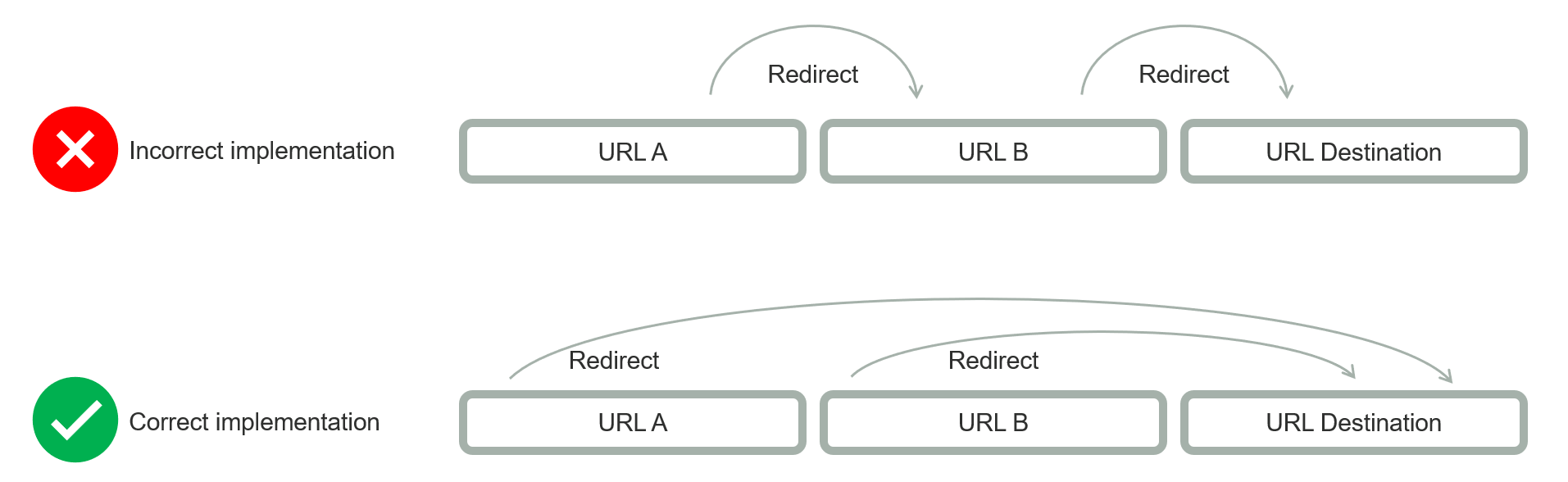
Typiske redirect fejl kan være såkaldte redirect kæder, hvor side A redirecter til side B, der så igen redirecter til side C. Best practice i disse tilfælde er at sørge for, at A og B redirecter direkte til C. Ligesom med døde interne links, er det heller ikke optimalt, hvis et redirect peger på en 404-side, da dette sender GoogleBot ned ad en blindgyde, hvor den ikke finder nyt indhold at crawle. Derfor bør du sikre, at redirects altid peger direkte på deres destination, og at destinationen er en fungerende side med statuskode 200.
Korrekt opsætning af robots.txt
Robots.txt har til formål at hjælpe dig med at styre, hvordan GoogleBot crawler din hjemmeside. Kort fortalt er robots.txt en simpel tekstfil, hvori du kan specificere hvilke dele af din hjemmeside du ønsker, at GoogleBot skal crawle. Endnu vigtigere kan du også blokere GoogleBot fra at crawle sider, du ikke ønsker skal findes på Google.
“Hvorfor skulle man have interesse i at blokere GoogleBot fra at crawle bestemte dele af ens hjemmeside?”, tænker du måske. Dette hænger sammen med begrebet crawl budget. Google crawler hver dag millioner af hjemmesider, hvilket er enormt ressourcekrævende. Derfor sætter Google nogle begrænsninger på, hvor meget og hvor ofte hver enkelt hjemmeside bliver crawlet. Dette kalder Google for crawl budget.
Med tanke på at bruge sit crawl budget så effektivt som muligt, kan det give mening at fortælle GoogleBot, hvilke sider den ikke behøver bruge ressourcer på. Dette gøres ved hjælp af “Disallow”-kommandoen, der angives i robots.txt filen. Sider du ikke ønsker crawlet og indekseret kan være login-sider, cms-sider, medlemssider og lignende. Ved at disallowe irrelevante sider sikrer du, at der er crawl budget nok til de vigtigste sider.
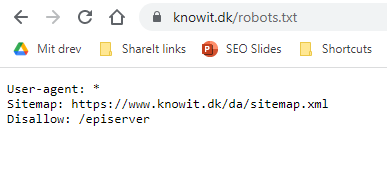
Her på knowit.dk har vi eksempelvis disallowet vores cms-sider ved at tilføje “Disallow: /episerver” til vores robots.txt
Du skal dog være meget varsom med at redigere i robots.txt, med mindre du har helt styr på, hvad du laver. Får du ved et uheld disallowed en forkert sektion af din hjemmeside, vil Google helt undlade at crawle denne.
Derfor er det en god idé at tjekke din robots.txt igennem for at sikre, at Google har adgang til at crawle dine vigtige sider og er blokeret fra ligegyldige sider.
XML sitemaps
Et sitemap er basalt set en lang liste af alle de URL’er, der findes på din hjemmeside. Denne liste kan GoogleBot bruge for at sikre, at den finder alle relevante undersider på din hjemmeside. Derfor er et sitemap et super vigtigt værktøj i forhold til at sikre optimal crawling.
Det er en god idé at linke til sitemappet fra din robots.txt-fil. Dette gøres ved at skrive Sitemap: [link til sitemap]. Gør du dette, vil GoogleBot altid kunne finde dit sitemap, og bruge det når den skal crawle din hjemmeside.
Det er også vigtigt at tilføje dit sitemap i Google Search Console, da dette igen er med til at sikre, at GoogleBot finder det. Det giver dig også mulighed for at følge med i crawl og- indekseringsstatus samt få besked om eventuelle fejl i dit sitemap.
Du tilføjer dit sitemap i Google Search Console ved at vælge sitemap ude i menuen til venstre. Herefter indsætter du URL’en til dit sitemap og trykker send.
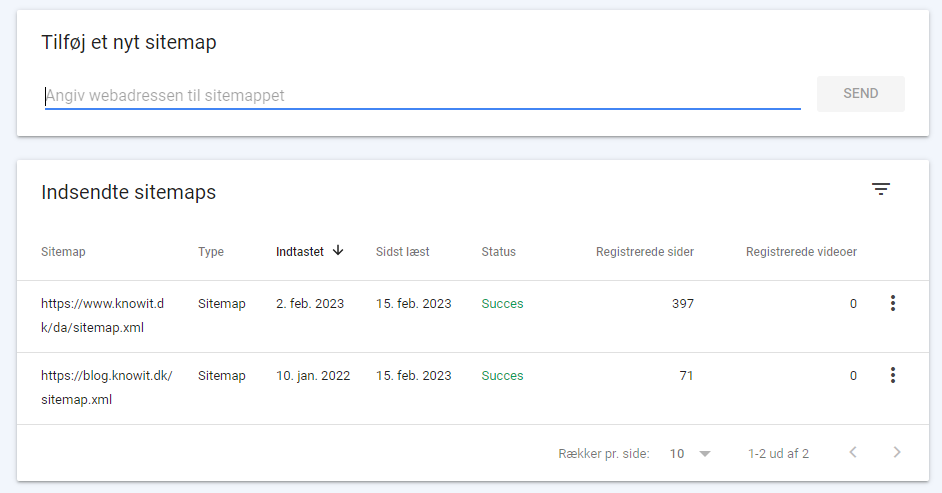
Endelig er det vigtigt at sørge for, at dit sitemap er opdateret. Dette gør du ved at ekskludere de sider, du ikke ønsker indekseret. Det kan være sider, du har disallowed i robots.txt, sider der er redirectet, 404-sider, eller sider der er sat til noindex. Ved at fjerne disse sider sikrer du, at GoogleBot ikke spilder ressourcer på at crawle dem, hvilket er godt for dit crawl budget.
2. Rendering
Når der er kommet styr på, at GoogleBot er i stand til at crawle din hjemmeside, er næste step at sikre, at GoogleBot kan forstå indholdet på de sider, den finder. Det er her begrebet rendering kommer ind i billedet.
Lidt forenklet er rendering processen, hvori den kode din hjemmeside består af oversættes til indhold, billeder og struktur, som vi mennesker kan læse og forstå. Med andre ord er det du ser, når du besøger en hjemmeside i din browser, den renderede version af den bagvedliggende kode.
For at Google skal kunne vurdere kvaliteten af indholdet på en hjemmeside, og dermed være i stand til at ranke den, skal Google kunne rendere siden. Google har nogle begrænsninger for, hvad de kan rendere, og det er godt at være opmærksom på de begrænsninger. Hvis Google eksempelvis ikke kan rendere dine kategoritekster, vil du ikke få den rankingværdi, som godt indhold giver. Derfor er det super vigtigt, at du sørger for, at din hjemmeside er opbygget på en måde, så Google kan rendere indholdet.

En hjemmeside består overvejende af tre elementer: html, css og JavaScript. Html og css er uproblematisk for Google at rendere. Helt så enkelt er det desværre ikke, når det kommer til JavaScript. Google kan i de fleste tilfælde rendere JavaScript, men nogle gange giver det problemer.
Derfor bør vi tage os nogle forholdsregler, så alle de SEO-mæssigt vigtige elementer på en side kan renderes af Google. Dette gøres ved at sikre, at disse elementer ikke er afhængige af JavaScript.
Du kan få en god indikation på, om din hjemmeside renderes korrekt af Google ved at bruge Googles Mobile Friendly test eller Google Search Consoles inspect tool. I disse værktøjer kan du indtaste en URL, og derefter se den renderede kode som Google ser den. Her er et eksempel på den renderede kode taget fra Google Mobile Friendly test, hvor der er indsat en side fra knowit.dk:
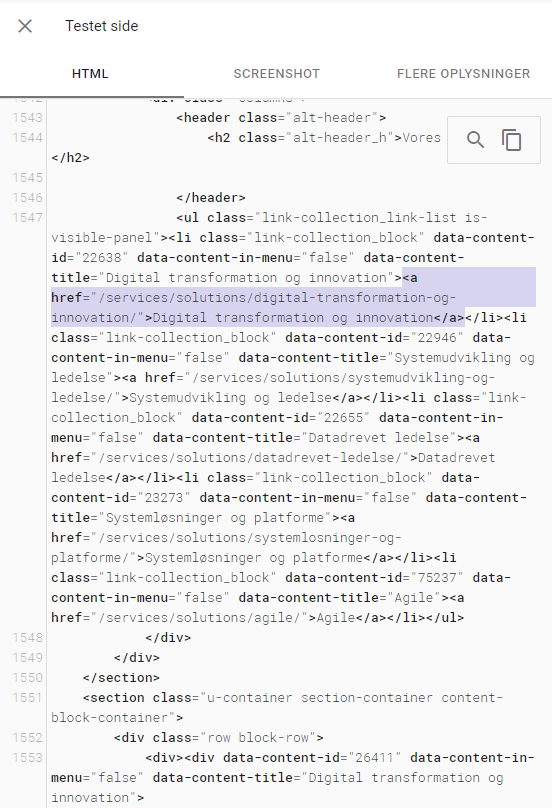
Ved at kigge i den renderede kode kan du tjekke, om de vigtige elementer kan ses af Google. Her er det relevant at se om al sidens tekst, links og billeder findes i koden. I dette tilfælde kan vi se at den indsatte sides menu-links kan findes i koden. Dermed ved vi, at Google også kan finde de vigtige links.
Opdager du, at centrale dele af din hjemmesides indhold ikke renderes, bør du fikse det. Der er flere måder at løse renderingsproblemer på, og den rigtige måde afhænger af, hvordan din hjemmeside er lavet. Derfor bør du tale med din udvikler om, hvordan I kan sikre, at Google kan forstå indholdet på jeres hjemmeside.
3. Indeksering
Når der er tjek på, at Google kan crawle og rendere indholdet på hjemmesiden, er det tid til at tage stilling til indeksering. Indeksering dækker over, hvilke undersider på din hjemmeside du ønsker skal være en del af Googles indeks. For at en side skal kunne findes af Google, skal den være i deres indeks.
Hvilke sider bør indekseres? Og hvad kan undlades?
Som udgangspunkt vil vi gerne have alle de sider, vi ønsker, skal ranke i Googles indeks. Dette er alle sider som enten giver brugeren værdi, eller som tjener et praktisk formål. Så alle informationssider, blogposts, produktsider, kategorisider, artikler og lignende bør indekseres.
Hvilke sider bør vi så undgå at få i indeks? Det er alle de sider, som vi ikke ønsker en bruger skal lande på fx arkivsider, password-beskyttede sider eller ressource-filer. Primært ønsker vi dog at undgå URL’er, der indeholder parametre, som bruges ved sorteringer, filtre eller interne søgeresultater. Har du eksempelvis en kategoriside, hvor der kan sorteres på pris, vil det ofte være en god idé ikke at lade de URL’er med sorteringsparametre indeksere.

Grunden til det er, at Google kun ønsker én version af den samme side i deres indeks. Har du en kategoriside med fx lamper, vil den minde utroligt meget om den samme side, hvor der blot er sorteret på lampe-størrelse. Dette kaldes duplikeret indhold og kan føre til, at den forkerte version af siden vises i Googles søgeresultater.
Derfor anbefaler vi, at det kun er den “rene” version af en side, der bliver indekseret, mens sider med parametre bør undlades.
Hvordan kan du styre indeksering?
Hvordan kan du så styre, hvilke sider der bliver indekseret – og hvilke der ikke gør? Dette er der primært tre metoder til:
- Noindex direktiv i robots-meta tag
- Canonical tags
- 301-redirects
Noindex benyttes ved at indsætte følgende tag på den side, du ikke ønsker skal indekseres:
![]()
Når GoogleBot møder dette tag i koden, vil den ignorere siden. Din udvikler vil formentlig kunne hjælpe dig med at opsætte en generel regel, der sørger for, at alle URL’er med et bestemt parameter får indsat noindex-tagget. Dermed skal det ikke indsættes manuelt på alle sider med sorteringsparametre, interne søgeresultater eller lignende.
Canonical-tags er en anden metode til at fortælle Google, at man ikke ønsker en given side i indeks. Canonical tagget ser ud som følger:
![]()
Forskellen fra noindex-tagget, der blot siger til Google, at den ikke skal indeksere en side, er at med Canonical-tag peger man på en anden side, man ønsker indekseret i stedet. Så hvis side B har et canonical-tag, der peger på side A, vil Google ikke alene vide, at B ikke skal indekseres, men også at side A er den side, man foretrækker skal ranke.
Endelig er der 301-redirects. Som vi har været inde på, leder et redirect brugeren eller Googlebot fra én side til en anden. Et redirect fortæller også Google, at den side der redirectes fra, ikke skal indekseres, og at Google i stedet skal fokusere på den side, der redirectes til. Redirects har også den fordel, at linkværdi og rankings overføres, hvilket er gavnligt, hvis man eksempelvis sletter gamle sider på ens hjemmeside.

Hvornår skal man så benytte noindex, canonical og redirects? Canonical bør benyttes, når du har to eller flere sider, der minder om hinanden, og du kun ønsker, at én af dem skal ranke. Det kan eksempelvis være en kategoriside, hvor der er mulighed for at sortere på en række elementer. I det tilfælde vil man typisk have en “ren” kategoriside og en masse variationer med sorteringsparametre. Her bør der opsættes canonical-tags fra siderne med parametrene, der peger på den rene version af siden. Derved fortæller du Google, at det er den side, der skal ranke.
Noindex er oplagt at benytte, hvis der er tale om en side, der ikke har et alternativ, som du ønsker skal ranke i stedet. Kan siden helt undværes, det kan eksempelvis være gamle sider på en hjemmeside der er flyttet, kan du med fordel redirecte disse sider i stedet for bare at noindexe dem, da de gamle siders link- og rankværdi derved overføres til de nye.
Sådan skaber du en god proces for arbejdet med teknisk SEO
Nu hvor vi har opnået en forståelse for de grundlæggende elementer i teknisk SEO, kan vi begynde at udforme en proces for, hvordan vi anvender denne viden til at optimere vores hjemmeside.

Gør status med en teknisk SEO analyse
Enhver proces med teknisk SEO begynder med at gøre status på hjemmesidens nuværende tilstand. Dette gøres typisk ved at lave en teknisk SEO-analyse, hvor man gennemgår hjemmesiden fra a til z, og tjekker om den lever op til alle de tekniske krav, der stilles til en hjemmeside.
En sådan analyse vil ende ud i en liste med problemer, der skal udbedres, og elementer der kan forbedres. Prioriteringen af sådan en liste vil ofte variere en smule, alt efter hvilken SEO-ekspert du spørger, og hvor mange ressourcer du har tilgængeligt, men de grundlæggende elementer vi har gennemgået her, bør altid have højeste prioritet, da de er forudsætningen for, at din hjemmeside overhovedet kan komme til at ranke.

Følg arbejdet til dørs
Når du er klar med en prioriteret liste over ting, der skal udbredes, vil det ofte være dine udviklere, der får til opgave at implementere ændringerne. Her er det dog vigtigt, at du og SEO-eksperten ved din side ikke smækker benene op og tænker “job done”. Der bør nemlig altid være en SEO-specialist med i implementeringsprocessen, da der ofte vil opstå spørgsmål og komplikationer i forbindelse med implementeringen.
Eksempelvis kan det være, at en foreslået forbedring af en eller anden grund ikke kan implementeres på din hjemmeside. I den situation er det en fordel, at en SEO-specialist har mulighed for at vejlede om de mest SEO-venlige alternativer. Når ændringerne er implementeret er det også en god idé at få en SEO-specialist til at validere ændringerne, så du er sikker på, at alt er gjort korrekt.

SEO er en løbende proces
Når I er nået i mål med de tekniske optimeringer, er det vigtigt ikke at hvile for meget på lauerbærene. SEO er nemlig en løbende proces. Kravene til hvad en moderne hjemmeside skal kunne, og Googles algoritmer, ændrer sig hele tiden.
Derfor er det vigtigt at holde sig opdateret på nye features og Googles opdateringer. I takt med udviklingen vil det nemlig være nødvendigt at forbedre din hjemmeside, så du ikke sakker efter konkurrenterne. Også her er det en fordel at have en SEO-specialist med i processen, da vedkommende vil kunne vejlede dig i forhold til værdien af nye features, og vurdere om de er relevante for netop din hjemmeside.
Hvis du al den snak om teknisk SEO har givet dig blod på tanden til fluks at komme i gang med fingerarbejdet, kan du hoppe en tur i blogindlægget her, som handler om, hvordan du lægger en SEO strategi, der opbygger og fastholder dit websites synlighed på den lange bane. Ikke bare det næste halve år. Og hvis du er interesseret i lidt (meget) mere snak om den tekniske del af SEO, kan jeg fanges her.


